The Ping Avalanche: How to Architect High-Throughput Aggregation and Ingestion Engines for Blog Directories
-

- June 28th, 2026
- 23 views

FREE SEO Topical Map Generator: Find Your Next Content Ideas
In the ecosystem of digital publishing communities, influencer directories, and content discovery hubs, discovery velocity dictates platform value. To bridge the gap between thousands of independent creators and brand marketers, a directory network must remain perfectly synchronized with the blogosphere. The system must allow creators to link their RSS feeds, register their platform domains, and push new article updates to centralized feeds instantaneously.
To deliver an exceptional community feed experience, the underlying system architecture must handle intense background processing workloads: parsing XML data payloads, scraping metadata fields, validating cross-domain backlink footprints, and checking Domain Authority (DA) rankings simultaneously.
However, a critical system vulnerability surfaces when an engineering team forces these external blog validations to run synchronously within primary web application threads. Unlike standard localized database operations, accepting automated XML-RPC pings or pulling data from external blog feeds introduces deep network dependencies. If thousands of registered blogs publish content or ping your platform concurrently, forcing the main web controllers to wait while verifying downstream domains will exhaust server pools, turning a wave of community activity into a frustrating platform-wide latency bottleneck.
The Core Performance Liabilities of Synchronous Feed Processing
Many community portals and directories build their article aggregation pipelines around basic cron routines or inline handlers because they are direct to implement during early release cycles. While checking a handful of manual submissions works well initially, it creates severe structural failures as the platform grows into an active hub with thousands of registered writers:
The XML-RPC Ping Congestion: Automated blogging tools (such as WordPress core engines) fire structured ping notifications to directories the exact second an author hits publish. Under heavy concurrent usage, thousands of incoming web requests choke the ingestion endpoint, leading to thread pool exhaustion.
The External Network Delay Penalty: To parse a pinged post, your server must hit the external blogger's site, read the RSS feed, and extract metadata tokens. If a publisher's server is down, misconfigured, or slow, your primary application thread remains frozen in an open loop, driving up system-wide response times.
The Metric Synchronization Gridlock: Aggregation hubs often update domain-level analytics—like refreshing third-party Moz DA metrics or updating city-wise indexing maps—directly during the ingestion block. Running these heavy lookup routines on active write paths deadlocks relational databases and stalls public content channels.
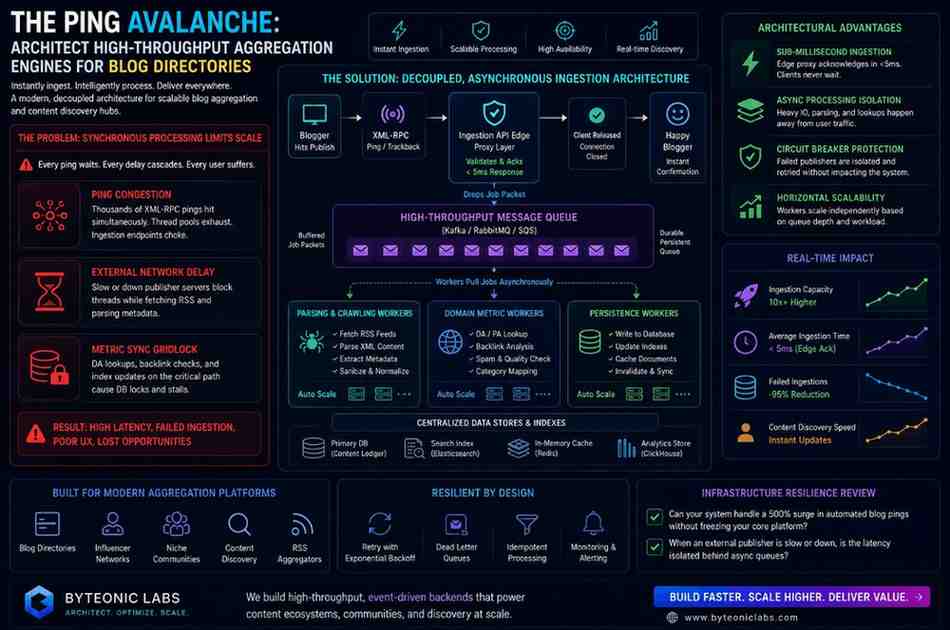
The Solution: Deploying Decoupled Buffer Brokers and Asynchronous Ingestion Workers
To guarantee absolute availability and sub-second rendering times across public directory directories during massive submission waves, senior systems engineers isolate web input endpoints from processing networks. This technical balance is achieved by implementing an Asynchronous Aggregation Broker backed by a Decoupled Validation Worker Cluster.
Instead of allowing external XML network lookups to touch active web channels, the architecture processes incoming ping traffic through a highly scaleable, message-driven design.
[Independent Blogger Hits Publish]
│
▼
┌─────────────────────┐
│ Ingestion API Edge │ ──(Validates ping token and
│ Ingestion Proxy │ releases client in <5ms)
└──────────┬──────────┘
│
(Drops Processing Job Packet)
▼
┌─────────────────────┐
│ High-Throughput │
│ Message Queue │
└──────────┬──────────┘
│
(Workers Pull Jobs Asynchronously at Safe Cadences)
▼
┌────────────────────┼────────────────────┐
▼ ▼ ▼
┌──────────────────┐ ┌──────────────────┐ ┌──────────────────┐
│ RSS XML Parsing │ │ External Domain │ │ Database Write │
│ & Scraping Node │ │ Metric Lookup │ │ Ledger Node │
└──────────────────┘ └──────────────────┘ └──────────────────┘
This uncoupled configuration introduces three vital layers of protection to a high-volume directory ecosystem:
Sub-Millisecond Ingestion Proxies: When an external blog script fires an update ping to your platform, it interacts solely with a lightweight edge proxy. The proxy registers the request metadata, drops an encrypted job token into an asynchronous queue (such as RabbitMQ or Apache Kafka), and immediately returns a success validation in under 5 milliseconds, instantly freeing up your server connection slots.
Asynchronous Crawling Isolation: High-throughput background worker containers continuously pull job tokens from the central queue at a sustainable, automated pace. These workers handle the heavy lifting entirely away from your public traffic: executing the external HTTP fetch, parsing the XML feed nodes, and scrubbing formatting errors without ever touching an active reader's session.
Circuit-Breaker Infrastructure Guardrails: If a registered blogger's server goes offline or faces heavy database timeouts, an automated circuit breaker trips. The background worker logs a "Retry Pending" flag inside an in-memory cache and returns the job to a delayed-retry stream, preventing a broken downstream site from deadlocking your primary production channels.
Technical Agility Over System Friction
Re-architecting active data pipelines, setting up distributed message brokers, and managing high-frequency background lookups without inducing platform downtime requires deep systems design experience. Most development teams looking to scale multi-niche blogging networks and directory ecosystems successfully rely on a solid
Providing your internal software engineering team with a clean, uncoupled data blueprint gives them the structural freedom to scale digital features safely with maximum velocity, absolute technical stability, and complete peace of mind.
The Aggregation Infrastructure Resilience Review:
Test System Modularity: If your platform experiences a sudden 500% surge in automated blog pings during peak morning publishing hours right now, can your backend ingest and route those text payloads natively via isolated streams, or will write limits freeze your core web interface?
Evaluate Fail-Safe Frameworks: When an external publisher's site encounters a critical server delay during a feed scan, is that connection latency isolated safely behind an asynchronous messaging layer, or does it pass backward to deadlock your primary content feeds?
To discover how to eliminate software bottlenecks and optimize your platform's backend architecture for secure, long-term operational efficiency, consult the systems architects at